This week: optimization algos to faster train NN, on large dataset.
Mini-batch gradient descent
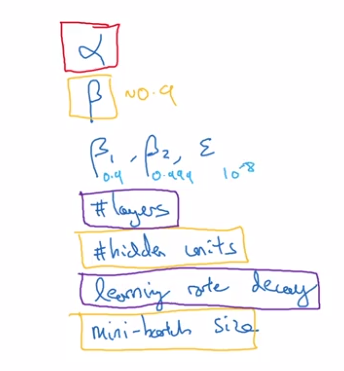
batch v.s. mini-batch GD
Compute J on m examples: vectorization, i.e. stacking x(i) y(i) horizontally.
X = [x(1), ..., x(m)]
Y = [y(1), ..., y(m)]
→ still slow or impossible with large m ...