Maxing周刊-ep1
昨天突发奇想想总结一下2022年, 发现还是用mermaid的甘特图做最简单. 鼓捣一番以后在朋友圈里发了这张图:
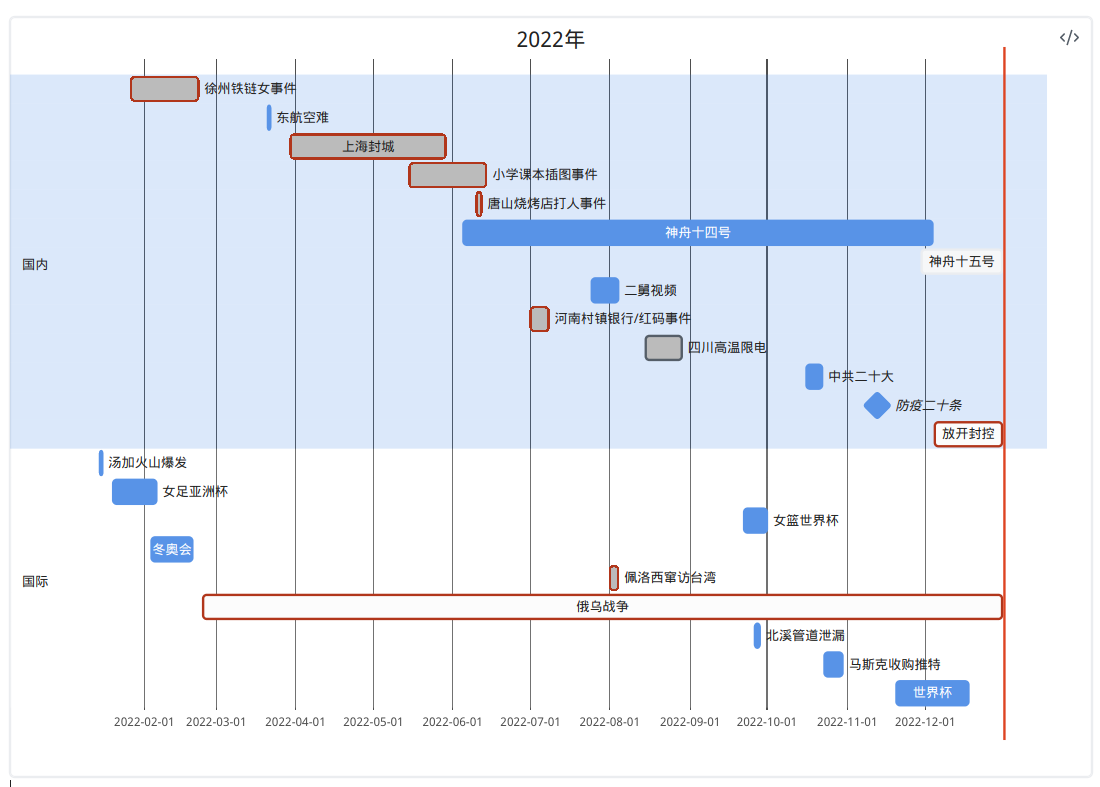
今天简单总结一下mermaid的甘特图(gantt chart)语法, 因为昨 …
前一阵考过了KDE的德语B1/A2考试, 我和老婆一致认为这可能是最水的德语考试. 简单总结一下考试经验.
学德语的误区
之前断断续续在 …
又是很久没更新博客和公众号, 昨天想更新一篇关于瑞士驾照的内容, 写作本身其实挺流畅, 但是在发布到博客和微信公 …
去年四月份我提交了国内驾照换瑞士驾照的申请, 经历了将近一年时间, 考挂了三次才终于在今年三月拿到了瑞士驾照 …
DJI运动相机拍摄的视频体积都比较大, 查了一下因为encoding是H264, 如果改成H265的话压缩率会高很多.
转换的命令是: (ref. stackoverflow)
ffmpeg -i input.mp4 -c:v libx265 -vtag hvc1 output.mp4
加上-qscale 0可以保持quality (不过好像对h265不管用? ref. stackoverflow)
保 …
Flutter(或者更宽泛的app开发)可以一句话总结为:
UI = f(state)
即app的当前界面(UI)反映了当前程序状态(state). Flutter的状态管理就是app根据当前app的state的显示和更新UI.
我们假设state是一个类型为T的 …
我的旧护照还有几个月过期, 这周在苏黎世中国总领馆更新了护照, 记录一下办理流程 -- 其实还是挺简单的, 而且速度很快 …

看了Resocoder和Robert Brunhage的两个视频, 这篇总结一下其中的内容(我其实还没实践过).
本文主要参考自:
- pub package
- Video by Robert Brunhage
- Tutorial by Resocoder
The problem
Flutter hooks想解决的问题是StatefulWidget的一些常见pattern太复杂 …