Part 0: Preliminaries
Each line in the ratings dataset (ratings.dat.gz) is formatted as:
UserID::MovieID::Rating::Timestamp ⇒ tuples of (UserID, MovieID, Rating)in ratingsRDD
Each line in the movies (movies.dat) dataset is formatted as:
MovieID::Title::Genres ⇒ tuples of (MovieID, Title) in ratingsRDD
487650 ratings and 3883 ...
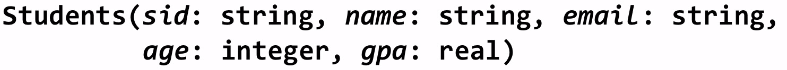
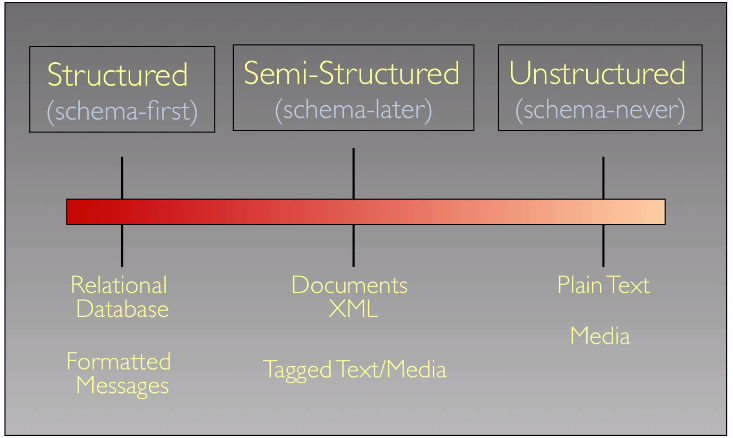 semi-structured data: apply schema after creating data.
semi-structured data: apply schema after creating data.