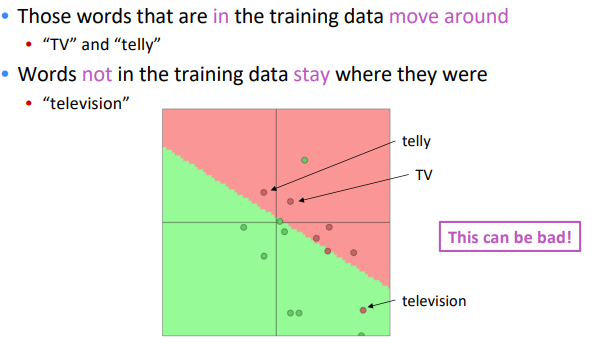
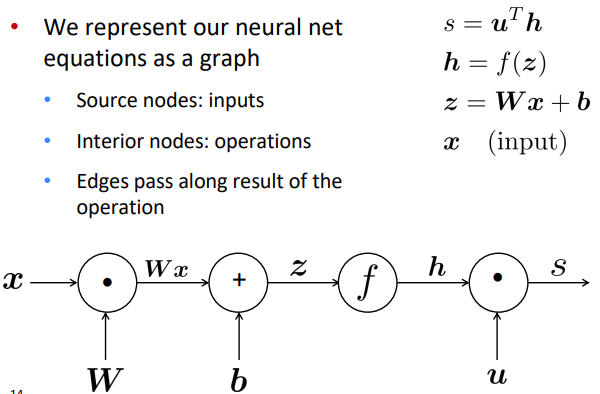
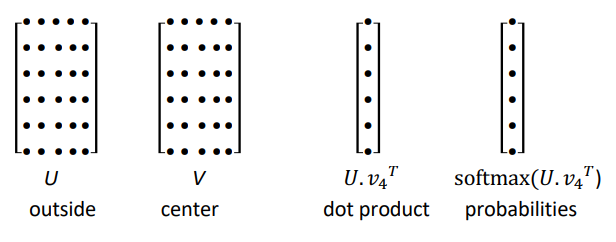
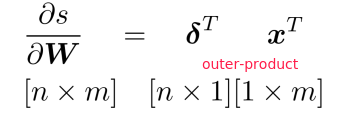Overview
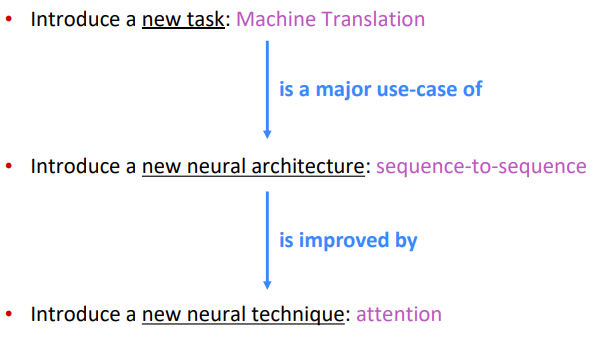
Background (Pre-Neural Machine Translation)
- machine translation (MT): sentence from source lang to target lang.
- 1950s: rule based, using bilingual dictionary.
1990s-2010s: Statistical MT (SMT)
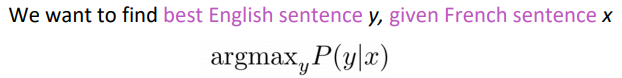
using Bayes rule: P(y|x) = P(x|y)*P(y) / P(x)
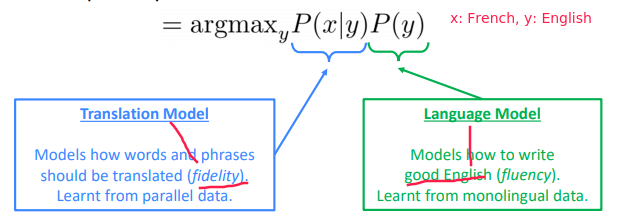
⇒ The language model we already learnt in prev lectures ⇒ To get the ...
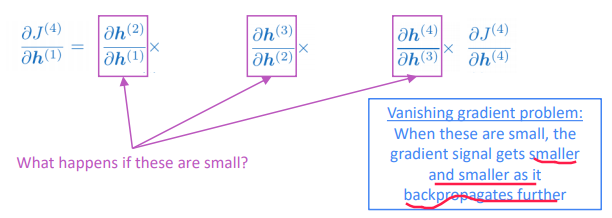
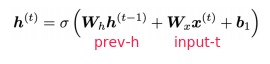 ⇒
⇒
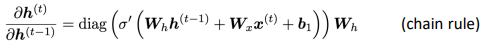
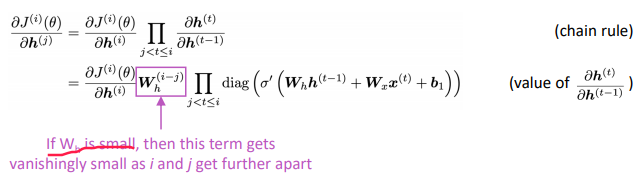
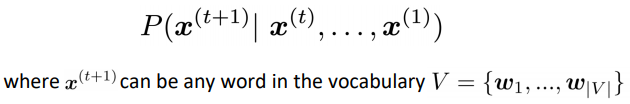





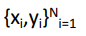
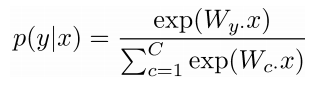
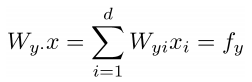
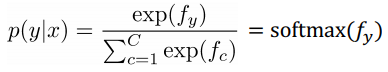
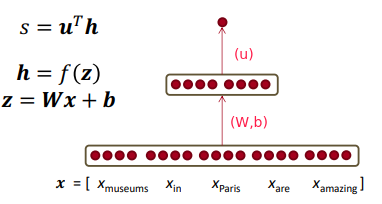
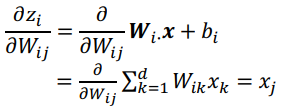
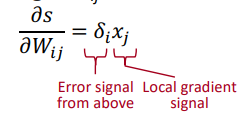 ⇒
⇒