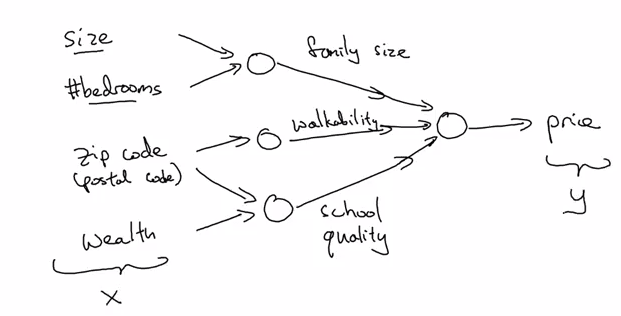
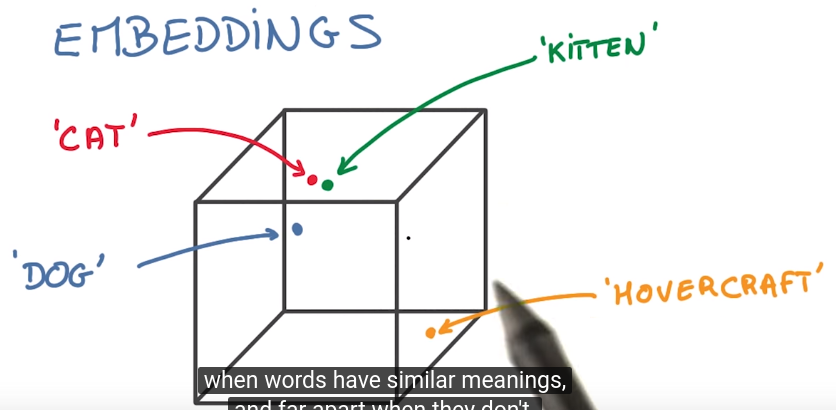
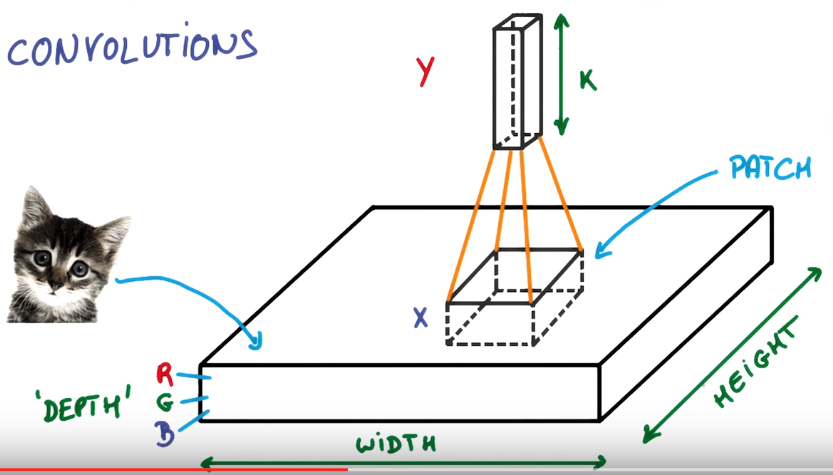
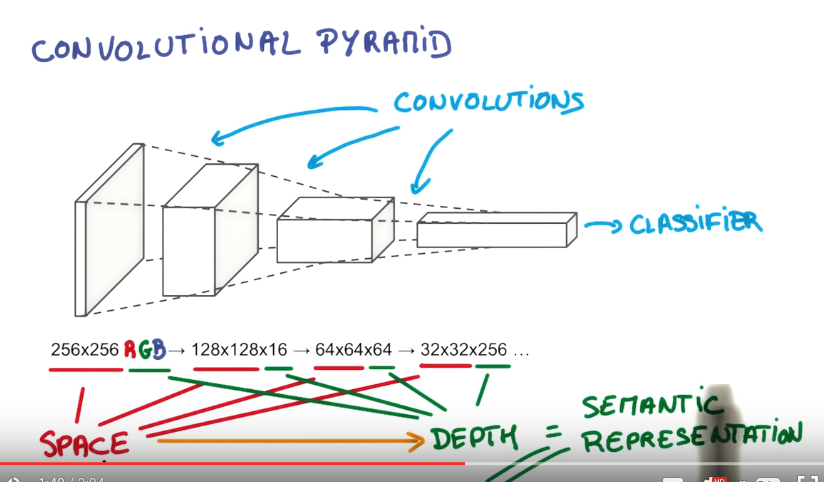
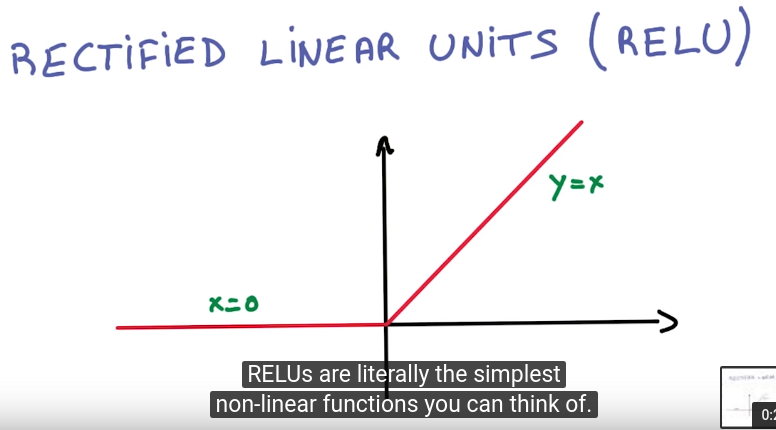
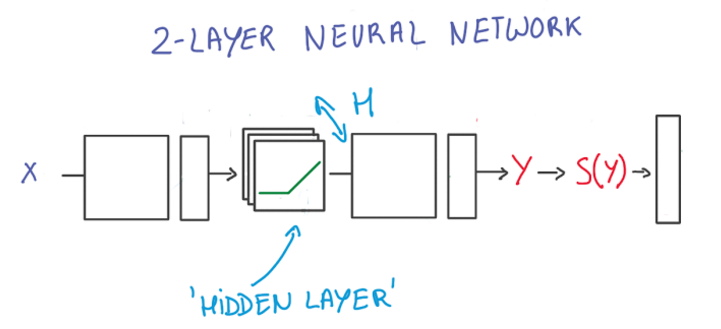
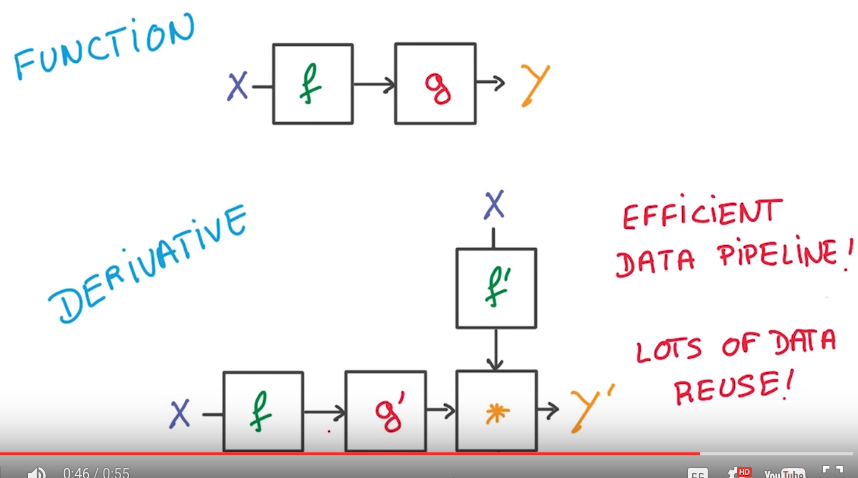
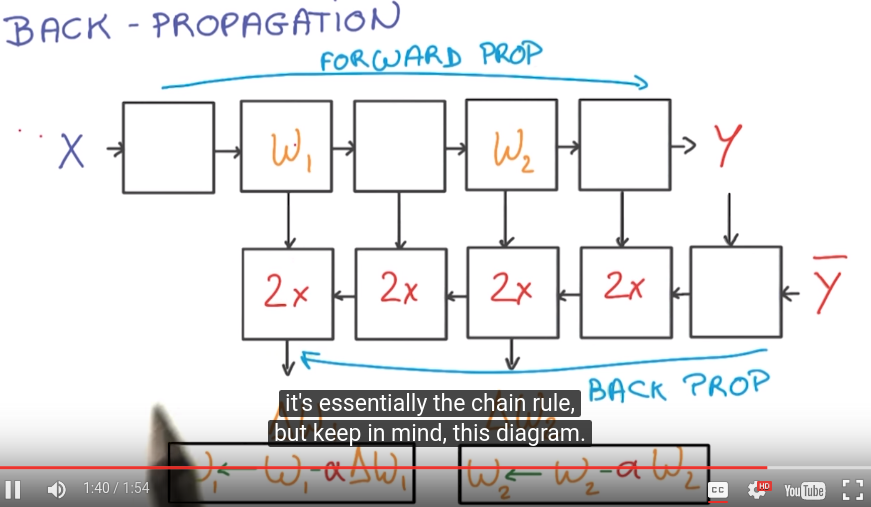
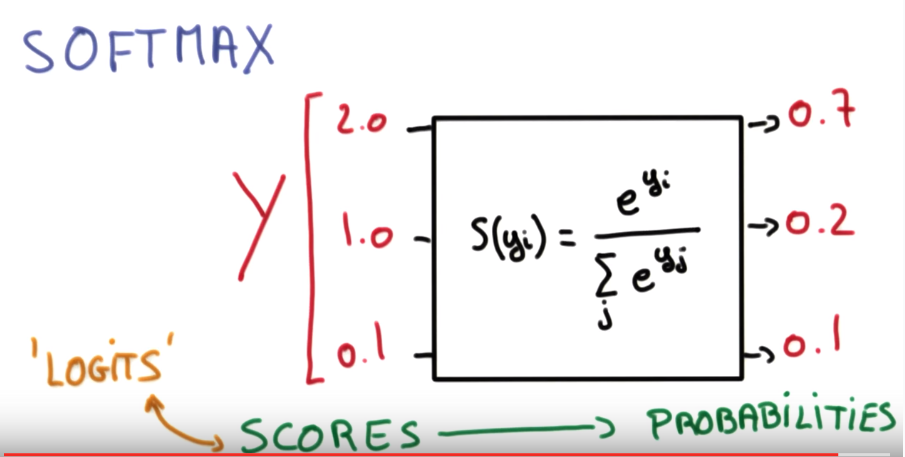
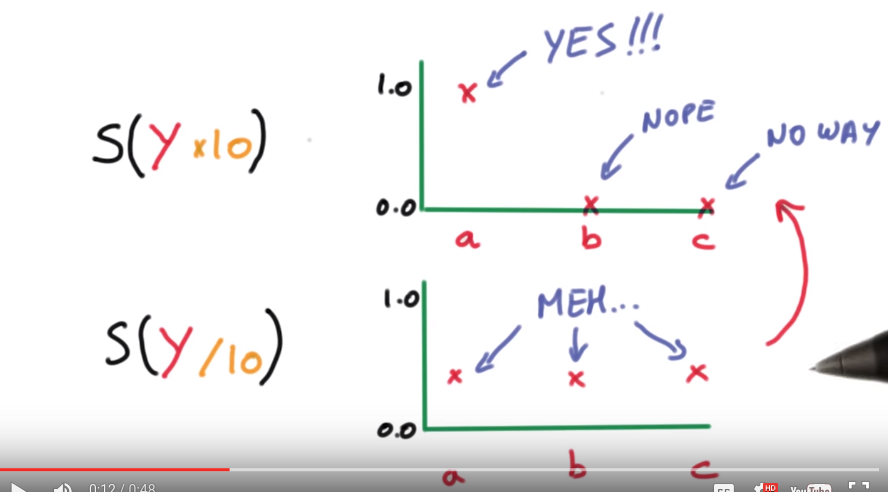
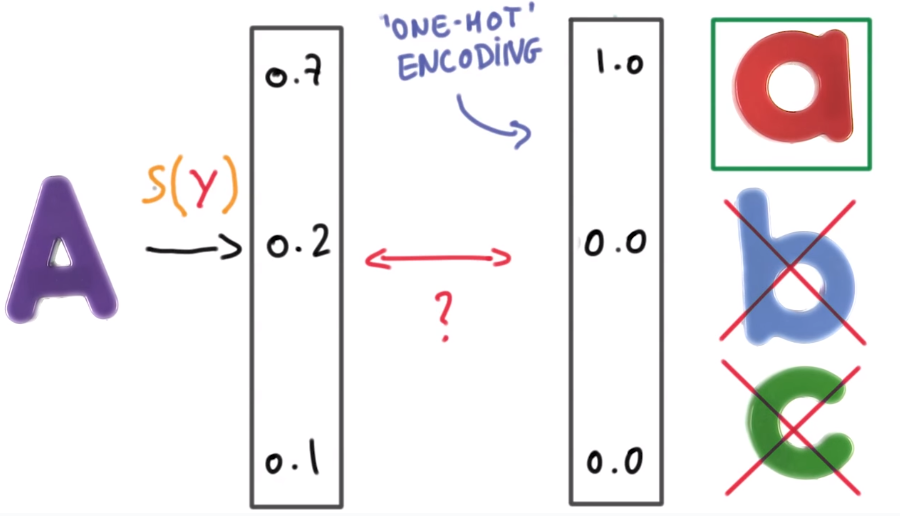
Deep L-layer neural network
Layer counting:
- input layer is not counted as a layer, "layer 0"
- last layer (layer L, output layer) is counted.
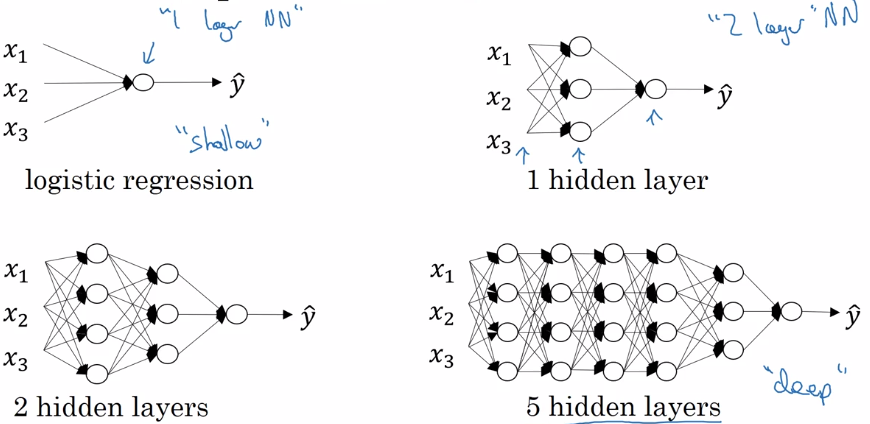
notation:
layer 0 = input layer
L = number of layers
n^[l] = size of layer l
a^[l] = activation of layer l = g[l]( z[l] ) → a ...