fundamental data types: stacks and queues
operations:
insert, remove, test empy, iterate,...
module programming: seperate interface and implementation
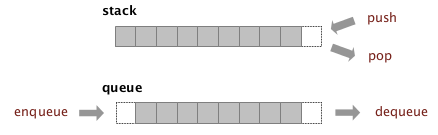
1. Stacks
ex. a stack of strings
-
API:
public interface StackoOfStrings{ void push(String item); String pop(); boolean isEmpty(); //int size(); }
implementation 1: using a linkedlist
insert/remove from the top of …
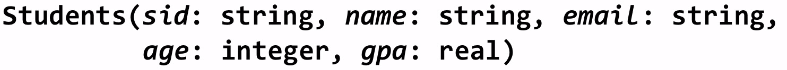
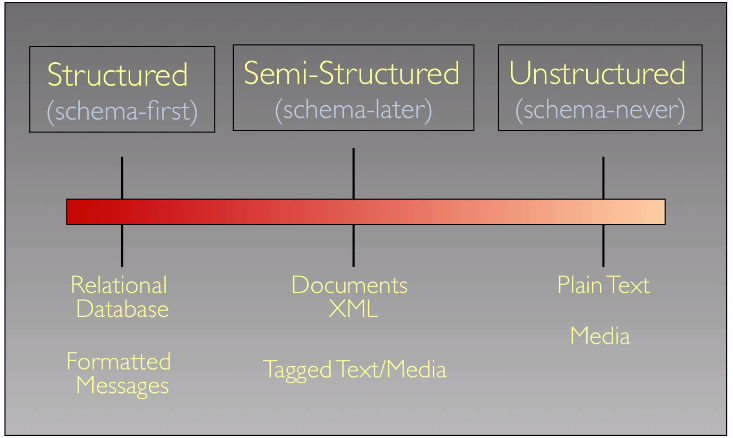 semi-structured data: apply schema after creating data.
semi-structured data: apply schema after creating data.