1. Regular Expressions
pb: pattern matching.
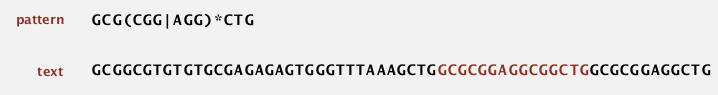
regular expression
Is a notation to specify a set of strings.
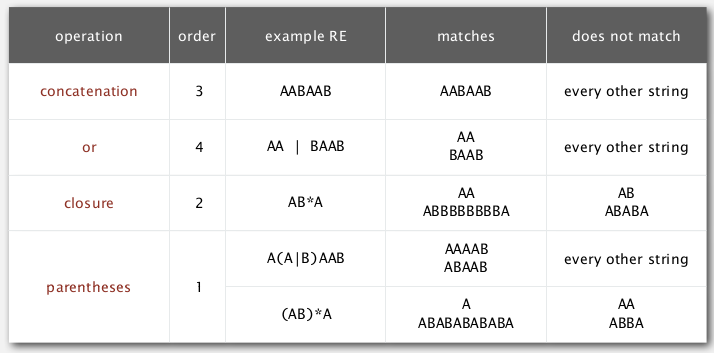
basic operations:
- concatenation
- or
- closure: "0 or more appearances of chars"
- parentheses
additional operations (added for convinence):
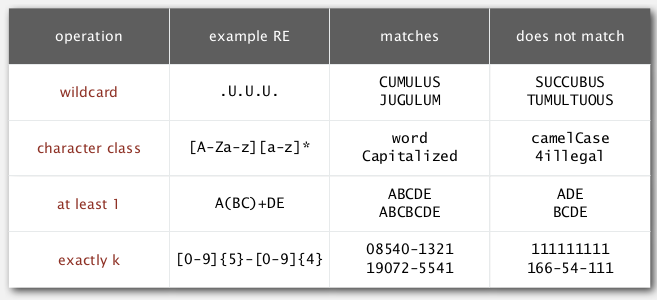
ex. [A-C]+ is equivalent to (A|B|C)(A|B|C)*.
吐槽名句: