week1
Created Friday 02 February 2018
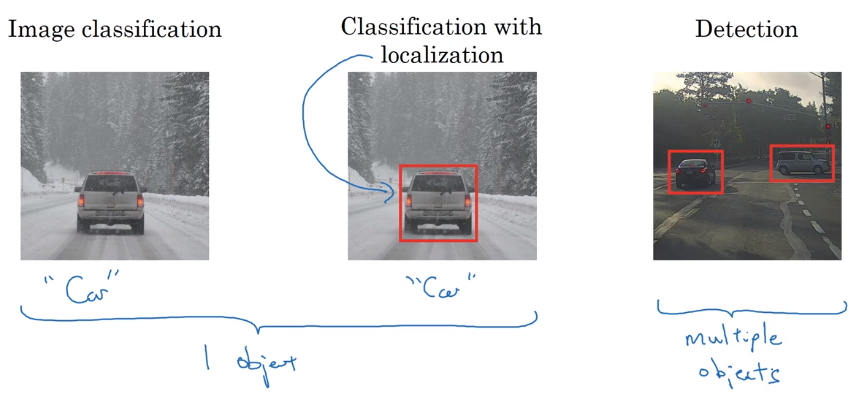
Why sequence models
examples of seq data (either input or output):
- speech recognition
- music generation
- sentiment classification
- DNA seq analysis
- Machine translation
- video activity recognition
- name entity recognition (NER)
→ in this course: learn models applicable to these different settings.
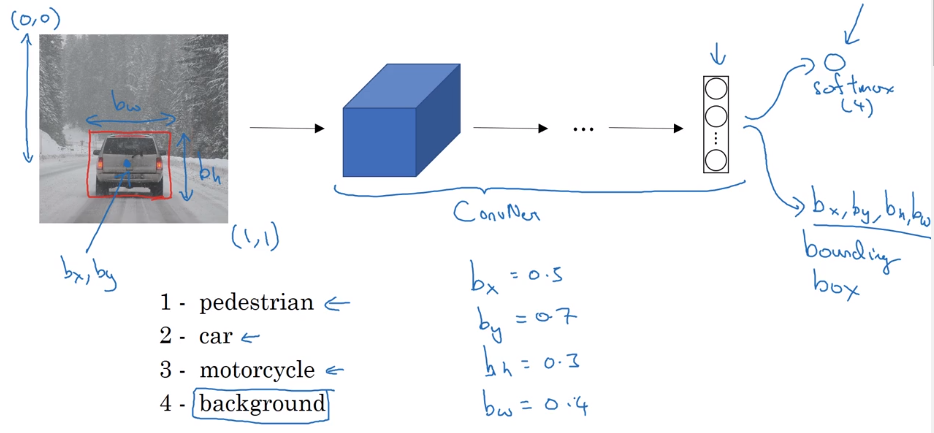
Notation
motivating example: NER (Each ...