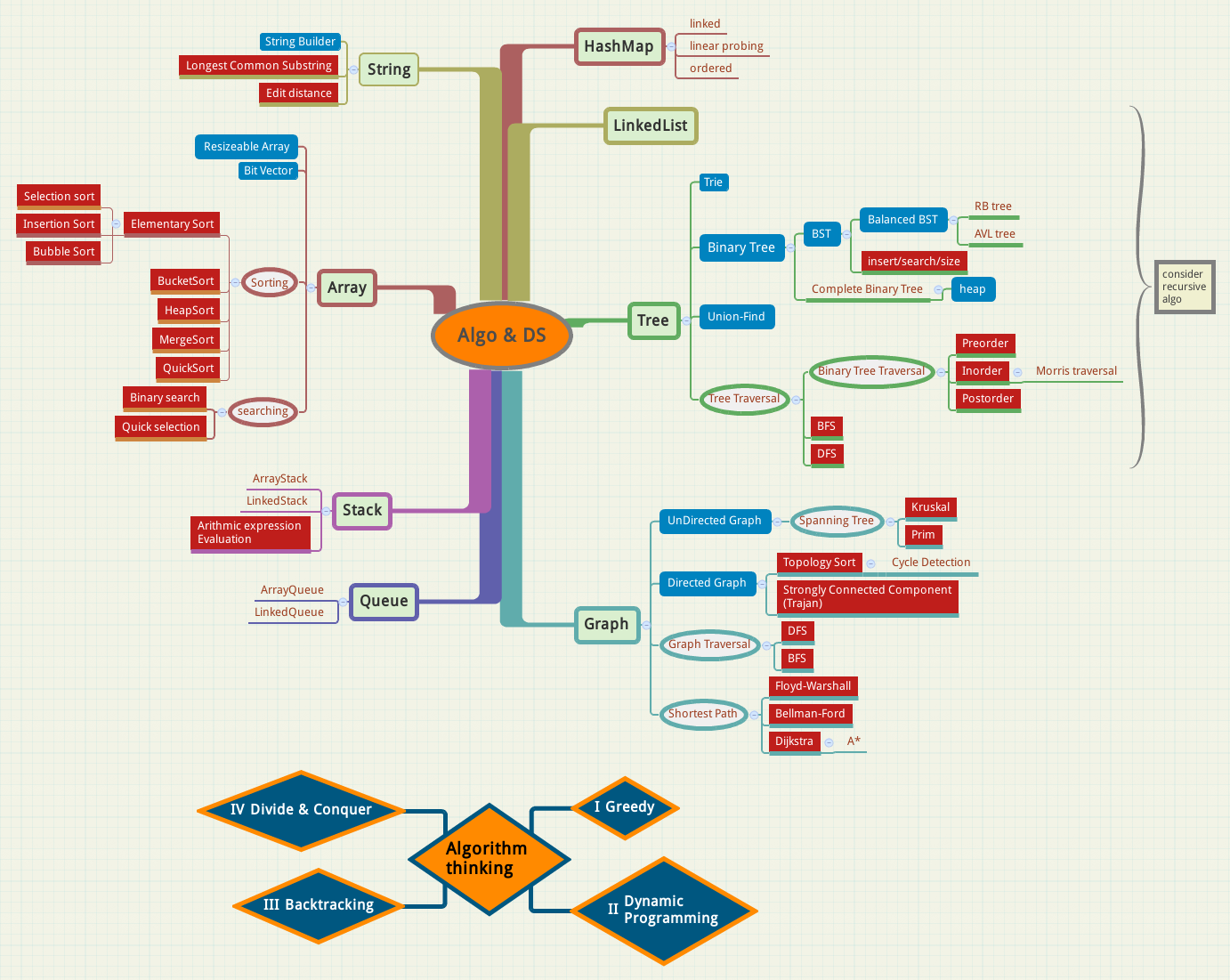
总结了一下C++ STL里面用的比较频繁的一些代码片段. (地址: https://github.com/X-Wei/cpp-demo-snippets/tree/master/STL)
cpp文档: http://en.cppreference.com/w/cpp
常用的library主要有:
<algorithm>, <vector>, <queue>, <set>, <map>, <cmath>
另外一个常见的cpp文件开头版本是:
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
#define forloop(i,lo,hi) for(int i = (lo); i <= (hi); i++)
#define rep(i ...