首先, 导入pandas
import pandas as pd
以及开启pylab: IPython里输入%pylab
http://www.bearrelroll.com/2013/05/python-pandas-tutorial/
基本操作
http://cloga.info/python/%E6%95%B0%E6%8D%AE%E7%A7%91%E5%AD%A6/2013/09/17/pandas_intro/
pandas和numpy的关系: pandas是建立在numpy上面的, pandas可以处理不同类型的数据集合(heterogeneous data set: DataFrame), numpy处理的是相同类型的数据集合(homogeneous data set: ndarray)
读写csv文件
read_csv()
df=pd.read_csv('data.csv')
说一下数据类型的问题:
- 返回类型数据帧(DataFrame):
type(df) = pandas.core.frame.DataFrame
df.columns包含了所有列的标签(字段名)
df.index包含了所有行的标签(可能没有的话, 就是一系列递增的数字了)
- 但是其中的每一列是Series类型:
type(df.dep)=pandas.core.series.Series - 然后可以将Series转换为numpy的ndarray:
array(df.dep)
to_csv()
没啥好说的..
df.to_csv('csvfilename')
要是不希望把index也作为一列写进csv文件的话, 就选择参数index=False
http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.to_csv.html?highlight=to_csv#pandas.DataFrame.to_csv
indexing & slicing
- 选择一列:
df['dep']或者df.dep - 选择前3行(前三条记录):
df[:2] - 使用标签选取数据:
df.loc[行标签, 列标签]
选择前两列:
df.loc[:,('one','two')]
或者用
df.loc[:,df.columns[:2]]
- 使用位置选取数据:
df.iloc[行位置, 列位置]
df.iloc[:,:2]
- 自动判断的切片:
df.ix[行位置或行标签, 列位置或列标签]
所以前面俩基本用不着了...
df.ix[:,('one','two')]
df.ix[:,:2]
- boolean indexing
ex. 选择dep是'PAR'的记录
hk[hk.dep == 'PAR'].head()
ex. 多个条件, 比如dep是'PAR', dst是'BHM':
hk[(hk.dep == 'PAR')&(hk.dst=='BHM')].head()
注意: 中括号里面的表达式, 每一个条件需要括号括起来, 中间的&不能用and, 等于号==不能用is.
文档里的一个表格:

设置小数精度 http://pandas.pydata.org/pandas-docs/stable/options.html?highlight=precision
设置小数点后六位的精度:
pd.set_option('precision',7)
注意六位精度的话要设置precision为7=6+1.
调整某一列的次序
df.reindex(columns=pd.Index(['x', 'y']).append(df.columns - ['x', 'y']))
http://stackoverflow.com/questions/12329853/how-to-rearrange-pandas-column-sequence
随机抽取几行 rand_idx = random.choice(df.index,9, replace=False) #要设置replace = False以防止重复! df.ix[rand_idx]
两个df相merge
- 两个df的column都一样, index不重复(增加行):
pd.concat([df1,df2])
- 两个df的index一样, column不同(增加列)
pd.concat([df1,df2], axis = 1)
adding/deleting columns
http://pandas.pydata.org/pandas-docs/stable/dsintro.html#column-selection-addition-deletion
- 新建一列, 加到最后面:
df['new_col']=xxx
- 想要把一列插进中间某一处, 使用df.insert:
df.insert(1, 'bar', df['one'])
- 删除一列, 只需用
del关键字:
del df['one_col']
- 两个Series组成一个dataframe:
pd.concat([s1, s2], axis=1)
- 重命名一列:
df=df.rename(columns = {'old_name':'new_name'})
或者:
df.rename(columns = {'old_name':'new_name'}, inplace=True)
http://stackoverflow.com/questions/20868394/changing-a-specific-column-name-in-pandas-dataframe http://www.bearrelroll.com/2013/05/python-pandas-tutorial/
apply() & map() & agg()
apply()
对dataframe的内容进行批量处理, 这样要比循环来得快.
df.apply(func, axis=0,...)
func: 定义的函数
axis: =0的时候对列操作, =1的时候对行操作
ex.
df.apply(self, func, axis=0,
map()
和python内建的没啥区别
df['one'].map(sqrt)
groupby()
按照某一列(字段)分组, 得到一个DataFrameGroupBy对象. 之后再对这个对象进行分组操作, 如:
df.groupby(['A','B']).sum()##按照A、B两列的值分组求和
groups = df.groupby('A')#按照A列的值分组求和
groups['B'].sum()##按照A列的值分组求B组和
groups['B'].count()##按照A列的值分组B组计数
agg()
对分组的结果再分别进行不同的操作... 参数是一个dict, 把每个字段映射到一个函数上来...... 说的不清楚, 直接看例子:
In [82]: df
Out[82]:
one two three
index
a 1 1 2
b 2 2 4
c 3 3 6
d NaN 4 NaN
In [83]: g=df.groupby('one')
In [84]: g.agg({'two': sum,'three': sqrt})
Out[84]:
two three
one
1 1 1.414214
2 2 2.000000
3 3 2.449490
甚至还可以对每一列进行多个处理操作:
In [100]: g.agg({'two': [sum],'three': [sqrt,exp]})
Out[100]:
two three
sum sqrt exp
one
1 1 1.414214 7.389056
2 2 2.000000 54.598150
3 3 2.449490 403.428793
具体见: http://stackoverflow.com/questions/14529838/apply-multiple-functions-to-multiple-groupby-columns
统计出现频率
方法1:
_hkhist=hk.groupby(groups).count().ix[:,0]#count of groupes
方法2:
hk.groupby('dep').size()
方法3:
(只适用于一列的情况)
hk.dep.value_counts()
把一列index转为column(不再作为index使用) http://stackoverflow.com/questions/20461165/how-to-convert-pandas-index-in-a-dataframe-to-a-column
比如, 原来的dataframe是三层index的, column只有一列(名字叫做'0'):
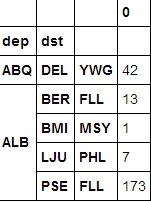
df.reset_index(level=2,inplace=True)
这样就可以把第三层的内容作为使用, 而不是作为index, 现在column有两列了, 再给两列命名一下:
hist_hub.columns = ['hub','occurrence']
就得到了:
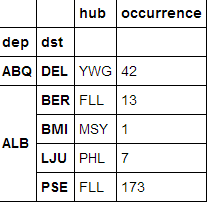
关于level这个参数: level : int, str, tuple, or list, default None Only remove the given levels from the index. Removes all levels by default
Plotting
http://cloga.info/python/2014/02/23/Plotting_with_Pandas/
统计出现次数, 画柱状图: g=hk.groupby('dep') dd=g['dst'].count() dd.plot(kind='bar')
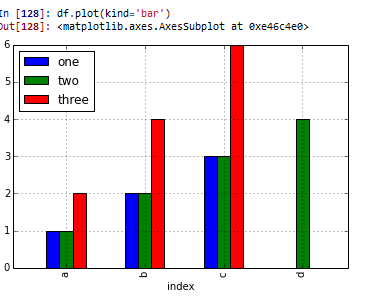 或者用pandas提供的:
http://pandas.pydata.org/pandas-docs/stable/basics.html#value-counts-histogramming-mode
nb=hk['#vol_hacker']
hist=nb.value_counts()*100.0/len(hk)
hist=hist.sort_index()
hist.plot(kind='bar')
或者用pandas提供的:
http://pandas.pydata.org/pandas-docs/stable/basics.html#value-counts-histogramming-mode
nb=hk['#vol_hacker']
hist=nb.value_counts()*100.0/len(hk)
hist=hist.sort_index()
hist.plot(kind='bar')
积累分布曲线 http://stackoverflow.com/questions/6326360/python-matplotlib-probability-plot-for-several-data-set
counts, start, dx, _ = scipy.stats.cumfreq(data, numbins=20)
x = np.arange(counts.size) * dx + start
plt.plot(x, counts, 'ro')
或者用pandas提供的东西也能做吧: http://pandas.pydata.org/pandas-docs/stable/basics.html#discretization-and-quantiling
hist2d 用pcolormesh http://www.physicsforums.com/showthread.php?t=653864
Disqus 留言