Here is a mindmap of the common algorithms and data structures, it can give an overview of the algorithmic terms.
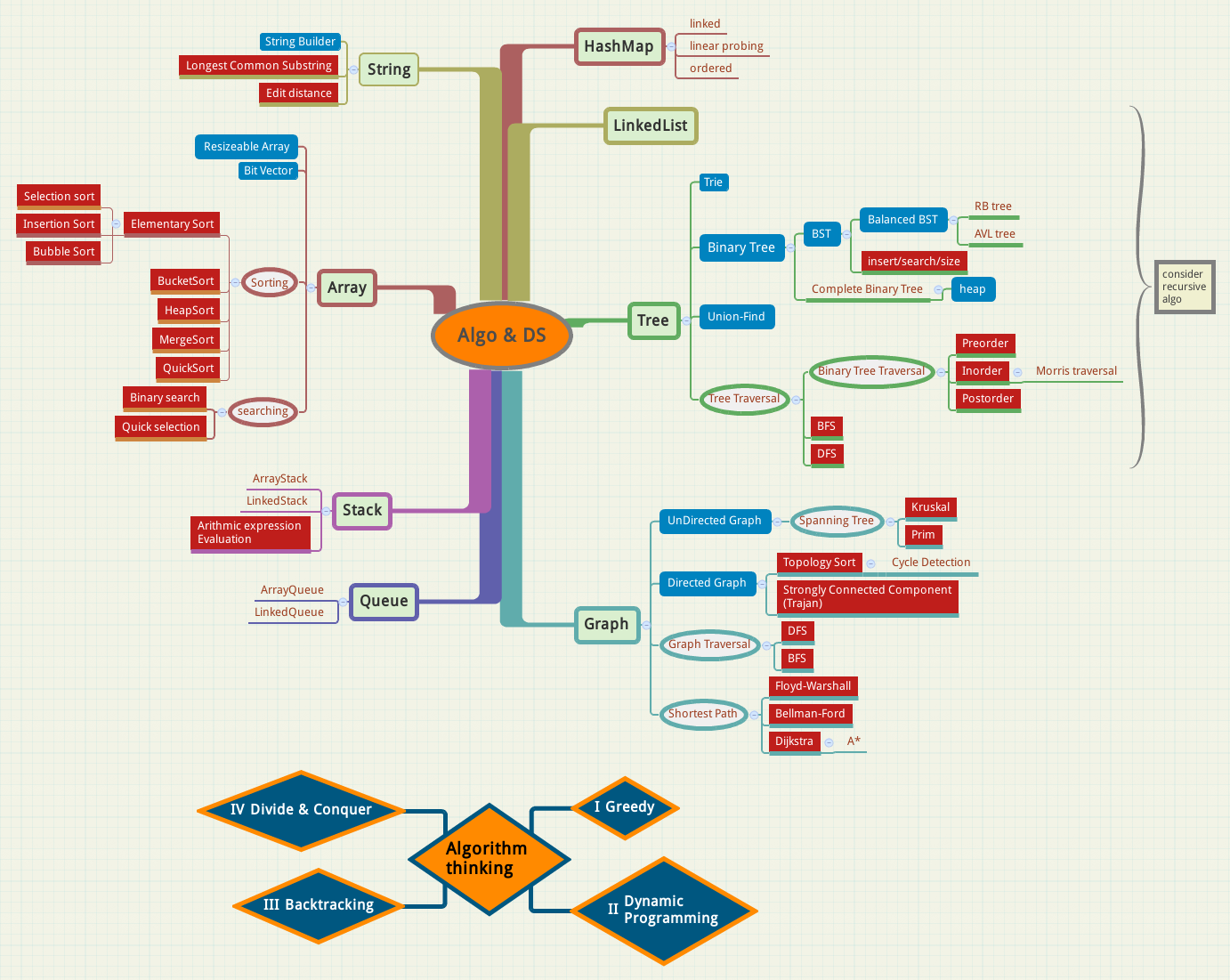
I shall update its content later on. And maybe write some blog entries on some of the items.
This mindmap is drawn using xmind.
Here is a mindmap of the common algorithms and data structures, it can give an overview of the algorithmic terms.
I shall update its content later on. And maybe write some blog entries on some of the items.
This mindmap is drawn using xmind.
python科学计算包的基础是numpy, 里面的array类型经常遇到. 一开始可能把这个array和python内建的列表(list)混淆, 这里简单总结一下列表(list), 多维数组(np.ndarray)和矩阵(np.matrix)的区别.
列表属于python的三种基本集合类型之一, 其他两种是元组(tuple)和字典(dict). tuple和list区别主要在于是不是mutable的.
list和java里的数组不同之处在于, python的list可以包含任意类型的对象, 一个list里可以包含int, string或者其他任何对象, 另外list是可变长度的(list有append, extend和pop等方法).
所以, python内建的所谓"列表"其实是功能很强大的数组, 类比一下可以说它对应于java里面的ArrayList<Object> .
ndarray是numpy的基石, 其实它更像一个java里面的标准数组: 所有元素有一个相同数据类型(dtype), 不过大小不是固定的.
ndarray对于大计算量的性能非常好, 所以list要做运算的时候一定要先转为array(np.array(_a_list_ ...
Scrapy是用来爬取数据的很流行的包, 这里小记一下. 以前几天做的一个爬虫为例子, 这个爬虫把韩寒一个app的前九百多期的文章抓了下来.
scrapy的安装参考: http://scrapy-chs.readthedocs.org/zh_CN/latest/topics/ubuntu.html
(直接pip安装的好像缺少什么包)
需要学习scrapy首先需要会XPath, 这是一种方便与在html/xml文档里查找所需元素的语句. 这个还是很好学的, 其实只需要花一刻钟时间看看w3school的教程, 就可以掌握够用的知识进行下一步了.
这里总结一下我觉得会用到的语句(不全, 不过经常用到):
//book 选取所有名字叫做book的元素bookstore/book 选取bookstore的子元素中所有叫book的元素//title[@lang='eng'] 选取lang属性为"eng"的所有title元素//titile/text() 选取title元素的文字内容descendant-or-self::text(): 选取自己或者所有后代节点的文字内容另外还有个在线测试XPath语句的网站 ...
INF580(programmation par contraintes) 大概是在X学到的最有用的一门课, 它让我能够用把运筹学(MAP557)里学到的东西和计算机结合起来: 用电脑的力量解决(大规模)运筹问题.
这门课的projet是去年巴黎谷歌举行的一个比赛的题目: 最优化谷歌街景拍照小车的路线. 做这个projet的三周里, 我和Manu从一开始信心满满, 到中间一筹莫展, 再到后来柳暗花明, 以及最后乘胜追击终于在今晚得到了近乎完美的解答, 非常精彩, 这里特意一记.
谷歌那次比赛的题目在这里(我们做的是Main Round的题目): https://sites.google.com/site/hashcode2014/tasks
简单来说, 就是已知巴黎的道路信息, 设法用八辆车(每辆车的行驶时间有限)从巴黎谷歌出发, 尽可能多的走遍巴黎的所有街道, 参赛者给出这些车的路线, 他们的分数就是这八辆车走过的街道的长度之和(重复走的街道不算分).
去年四月份我们也参加了这个比赛, 不过当时纠结于如何设计每辆车的路线, 最后只是用了贪心算法, 再加上一点点的随机, 得到的结果并不好... 当时ENS的人包揽了前三名, 而且比赛后进一步把分数刷到了满分: 他们的路线可以把所有街道都跑遍.
这学期学了INF580以后, 手里有了 ...
在处理大量数的时候, 如果输出类似 "process i out of n files..." 这样的内容来指示进度的话, 虽然可以显示目前的进度(用来安慰等待的心情...)但有个问题是, 如果输出了太多行(比如一万行...), 就看不到前面的内容了...
所以想找一个命令行下面的进度条, 其实python已经有了(不止一个)进度条的包了, 比如progressbar, 但是不知为什么这个包在windows下面没有能做到刷新显示 -- 就是刷新进度的时候, 没有把原先那一行去掉, 而是在下面再输出了一行... (不过后来在linux下面使用这个包是没问题的, 好奇怪...)
所以想办法自己写了一个, 发现要实现一个简单的进度条还是很简单的, 关键就是使用\r, 这样会把光标移动到当前行的开头: 这样下次输出的时候就会把原先的内容冲掉了.
代码只有不到二十行:
import sys
class SimpleProgressBar():
def __init__(self, width=50):
self.last_x = -1
self.width = width
def ...以前虽然也用过正则表达式(比如那个饮水思源的PPP版图片下载器...)但是那时候基本上是网上到处搜 然后把代码拿过来改, 没有系统的学过这个东西. 前一段实习一开始的时候要处理很大量的文本, 从文本里提取出需要的信息, 所以用到了不少的正则表达式, 也好好的学了一下, 现在回来进行一下总结.
很多时候,我们需要在文本里寻找满足一种模式(pattern)的一段子字符串(substring), 注意是一种模式而不是某一个具体的字符串. 举个例子, 在一段文本里寻找这里面出现的所有的网址, 那么对应的模式就是:
"以
www.开头, 中间有一些东西(可以是字母也可以是数字等), 最后以.com/.org/.edu...结尾的所有的字符串"
再比如, 要查找文本中出现的电话号码, 电话号码的格式是区号加横线再加号码, 那么模式就应该是:
"以3个或4个数字开头, 三个或四个数字之后跟一个横线, 横线后再跟7个或8个数字"
再再比如, 要查找出现的电子邮件地址, 那么模式大概是:
"以字母或数字或下划线开头, 之后跟着一个@符号, @符号以后一些用点分隔的字母或数字, 最后应该以.com/.org/.edu等结束 ...
Learning IPython for Interactive Computing and Data Visualization这本书的前两章的笔记, 这本书还被放在了IPython官网上, 虽然只有一百页多一点点, 但是讲的内容却很丰富, 介绍了IPython, numpy, pandas以及并行计算等方面.
(在开始系统学IPython之前简单使用过IPython, 那时候我还是更喜欢bpython的代码提示功能...)
?或者双问号??, 将会输出详细的信息(按q退出), ??的信息更加详细些_, __, ___保存最近三次的输出; _i, __i, ___i保存最近三次的输入(作为字符串保存)cd, pwd,ls等 ...首先, 导入pandas
import pandas as pd
以及开启pylab: IPython里输入%pylab
http://www.bearrelroll.com/2013/05/python-pandas-tutorial/
http://cloga.info/python/%E6%95%B0%E6%8D%AE%E7%A7%91%E5%AD%A6/2013/09/17/pandas_intro/
pandas和numpy的关系: pandas是建立在numpy上面的, pandas可以处理不同类型的数据集合(heterogeneous data set: DataFrame), numpy处理的是相同类型的数据集合(homogeneous data set: ndarray)
python的pickle/unpickle机制可以非常方便的保存一些计算的中间结果, 这一点java虽然也可以做到, 但是java里面的包的名字实在是长的让人记不住...
不过今天在使用pickle的时候遇到了一个很奇怪的问题.
是这样的, 原本写了一个程序main.py, 这个程序里进行了一些计算并且pickle下了这些内容, 后来我觉得一个程序main.py写这么多实在太长了, 于是就把那些辅助函数以及class的定义通通放进了一个util.py文件里. 并且在main.py的第一行写上:
from util import *
按理说这应该没有问题, 和一个main文件时运行的效果相同的, 但是当我运行的时候却显示util.py里面这行unpickle的语句有错误:
airport_info = pk.load(file('airport_info.dict', 'rb'))
>>AttributeError: 'module' object has no attribute 'Airport'
其中Airport是我定义的一个类, 本来在main.py里面, 后来被我移动到了util.py里面...
感觉很奇怪, 于是去水源求助 ...
据说这本书是最好的入门读物, 况且只有100来页 (减掉前面后面那些扯淡的 不到100页...)
那就用这本书过一下py的基本知识点吧! 看完以后收获不少, 把py涉及的很大一部分都讲到了. 这本书已经是够压缩的了, 不过我还是边看边自己再压缩了一遍(写在zim笔记里).
我看的是1.20版本, 2004年的, 因为这个版本针对的是py2.x, 作者主页上现在的版本针对的是py3. 另外感觉没必要看中文翻译版, 因为这里用的英语比较简单, 而且有的时候中文翻译反而不如原文表达的恰当.
扯淡...
There are two ways of using Python to run your program - using the interactive interpreter prompt or using a source file.
Anything to the ...