R里面的统计函数有很多, 这里只用线性模型lm以及(一维)非参估计最常用的三个smoother: Nadaraya-Watson kernel(NW, ksmooth), Local Polynomial(LP, loess), Smoothing Spline(SS, smooth.spline). 用这三个smoother作为例子, 介绍R里面统计回归的一些用法.
数据的形式是:
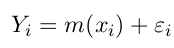
目标是估计函数m(). 例子使用R自带的cars数据集, 它包含两列: 汽车速度speed和刹车距离dist.
> data(cars)
> summary(cars)
speed dist
Min. : 4.0 Min. : 2.00
1st Qu.:12.0 1st Qu.: 26.00
Median :15 ...