Part 0: Preliminaries
Each line in the ratings dataset (ratings.dat.gz) is formatted as:
UserID::MovieID::Rating::Timestamp ⇒ tuples of (UserID, MovieID, Rating)in ratingsRDD
Each line in the movies (movies.dat) dataset is formatted as:
MovieID::Title::Genres ⇒ tuples of (MovieID, Title) in ratingsRDD
487650 ratings and 3883 movies
⇒ Since the key is an integer and the value is a unicode string, we can use a function to combine them into a single unicode string (e.g., unicode('%.3f' % key) + ' ' + value) before sorting the RDD using sortBy().
Part 1: Basic Recommendations
naive method: always recommend the movies with the highest average rating... ⇒ 20 movies with the highest average rating and more than 500 reviews
movieNameWithAvgRatingsRDD: (avgRating, Title, nbRatings)
Part 2: Collaborative Filtering
MLlib: https://spark.apache.org/mllib/
Collaborative filtering is a method of making automatic predictions (filtering) about the interests of a user by collecting preferences or taste information from many users (collaborating). The underlying assumption of the collaborative filtering approach is that if a person A has the same opinion as a person B on an issue, A is more likely to have B's opinion on a different issue x than to have the opinion on x of a person chosen randomly.
一图胜千言:

Matrix Factorization
CF问题实际上是矩阵分解的问题: We have a matrix whose entries are movie ratings by users (shown in red in the diagram below). Each column represents a user (shown in green) and each row represents a particular movie (shown in blue).
其中rating矩阵(用户/电影矩阵)只有一些项的值存在(即用户打分的那些项), 所以要用分解后的两个矩阵之乘积来估计rating矩阵中的缺失项.
With collaborative filtering, the idea is to approximate the ratings matrix by factorizing it as the product of two matrices: one that describes properties of each user (shown in green), and one that describes properties of each movie (shown in blue).
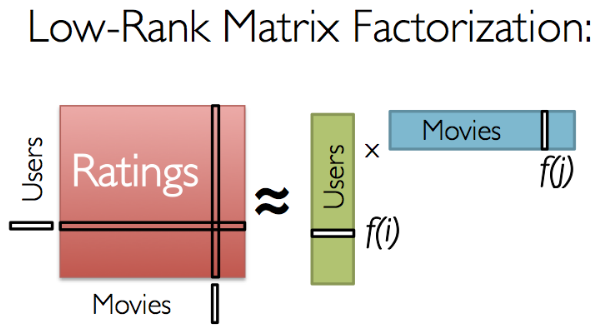
若N个用户, M个电影 ⇒ 把rating矩阵(NM)分解为 一个Nd矩阵(user矩阵)与一个dM(movie矩阵*)矩阵之积.
其中d个维度可以有(隐含的)意义: 比如f[j]第一个维度代表了电影j中动作片的成分, f[i]的第一个维度表示用户i对动作片的喜爱程度, 以此类推... 所以f[i]与f[j]的内积就可以是用户i对电影j的评分的一个不错的预测.
假设f[j]已知, 那么f[i]要满足: 对那些用户i已经打过分的电影(即r_ij存在)上的估计偏差最小:
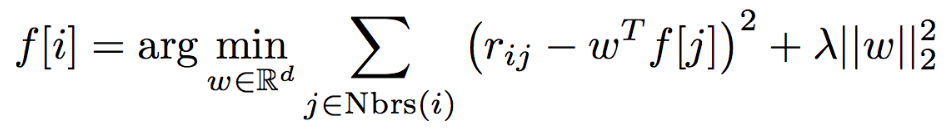
(后面加上的那一项是正则项: 不希望f[i]的模过大)
不过前面的假设, "f[j]已知"这个条件其实并不成立 ⇒ Alternating Least Squares algorithm: 交替优化f[i]和f[j]的取值, 每次固定一个, 而优化另一个, 交替进行, 直到收敛(好像Kmeans也是利用的这种方法).
first randomly filling the users matrix with values and then optimizing the value of the movies such that the error is minimized. Then, it holds the movies matrix constrant and optimizes the value of the user's matrix.
train-test-validation split
⇒ break up the ratingsRDD dataset into three pieces:
- A training set (RDD), which we will use to train models
- A validation set (RDD), which we will use to choose the best model
- A test set (RDD), which we will use for our experiments
trainingRDD, validationRDD, testRDD = ratingsRDD.randomSplit([6, 2, 2], seed=0L)
Root Mean Square Error (RMSE)
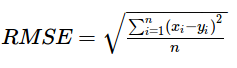
compute the sum of squared error given predictedRDD and actualRDD RDDs.
Both RDDs consist of tuples of the form (UserID, MovieID, Rating)
alternating least square of MLllib
https://spark.apache.org/docs/latest/api/python/pyspark.mllib.html#pyspark.mllib.recommendation.ALS ALS takes a training dataset (RDD) and several parameters that control the model creation process.
The most important parameter to ALS.train() is the rank, which is the number of rows in the Users matrix (green in the diagram above) or the number of columns in the Movies matrix (blue in the diagram above). (In general, a lower rank will mean higher error on the training dataset, but a high rank may lead to overfitting.)
貌似ALS接受一个(userid, itemid, rating)的RDD作为输入, 预测时接受一个(userid, itemid)的RDD作为输入, 返回一个(userid, itemid, rating)的RDD. (也就是说, 前面的notation在这里继续被使用了).
model = ALS.train(trainingRDD, rank, seed=seed, iterations=iterations,
lambda_=regularizationParameter)
predictedRatingsRDD = model.predictAll(validationForPredictRDD)
可以在这里查看job详情: http://localhost:4040/jobs/
compare model
Looking at the RMSE for the results predicted by the model versus the values in the test set is one way to evalute the quality of our model. Another way to evaluate the model is to evaluate the error from a test set where every rating is the average rating for the training set. ⇒ 这里没有太理解, 难道是说test set 的平均rating预测结果和training set的平均rating应该比较接近么?? ⇒ 终于明白了: "Your model more accurately predicts the ratings than using just the average rating, as the model's RMSE is significantly lower than the RMSE when using the average rating."
- 求一个tuple rdd最后一列的和的时候, 需要先map成最后一列再reduce:
trainingRDD.map(lambda x:x[-1]).reduce(lambda x,y:x+y)
直接写reduce(lambda x,y:x[-1]+y[-1])貌似是不行的
Disqus 留言