除了上次介绍的minhash方法以外, 还有一种常见的hash方法, 叫做simHash. 这里做简要介绍.
这个hash函数的背景和上次一样, 还是考虑把文本抽象为ngram的集合:
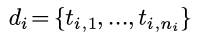
然后相似度依旧是Jaccard similarity:
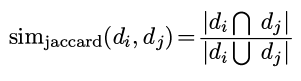
simHash
simHash的方法听上去比minHash还要简单:
- 对一个文档d中的每一个term(ngram, shingle) t, 计算其hashcode(比如用java内建的
Object.hashCode()函数) hash(t). - 把d中所有term的hash(t)合成为一个hashcode作为d的hashcode simHash(d): simHash(d)的长度与hash(t)相同, simHash(d)的第k个bit的取值为所有hash(t)第k个bit的众数.
写成数学表达式很吓人, 其实只不过不断在{0,1}和{-1,+1}之间变而已, 总之就是对所有hash(t)的每一位进行统计, 如果1多就放1, 否则就放0...
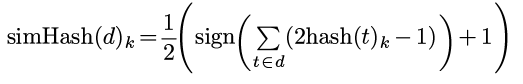
关于为什么simHash可以满足近邻hash的条件(即两个文档jacccard sim越大, 其simhash相等的可能性越大), 不知道... 不过可以参考这个链接: http://matpalm.com/resemblance/simhash/
simHash VS minHash
下面来比较一下二者的差别.
首先是表示方式:
- simHash只需要直接拿term的集合即可使用
- minHash需要首先建立字典, 然后用一个binary的向量(长度为字典长度)表示一个文档
其次是取值范围:
- simHash得到的hash范围取决于应用到每个term上的hash函数的范围, simHash与所有term的hash位数相同.
- minHash的范围等于字典的长度, 如果字典里有M个term那么minHash取值在1到M之间.
但是minHash也有优点:
- 要生成不同的simHash比较困难, 取决于应用在每个term上的hash函数有多少种.
- 生成不同的minHash非常容易: 每次shuffle就可以对一篇文章生成不同的minHash.
所以如果我们想要用多个hash来索引一个文章的时候, minHash可以很容易实现.
Disqus 留言