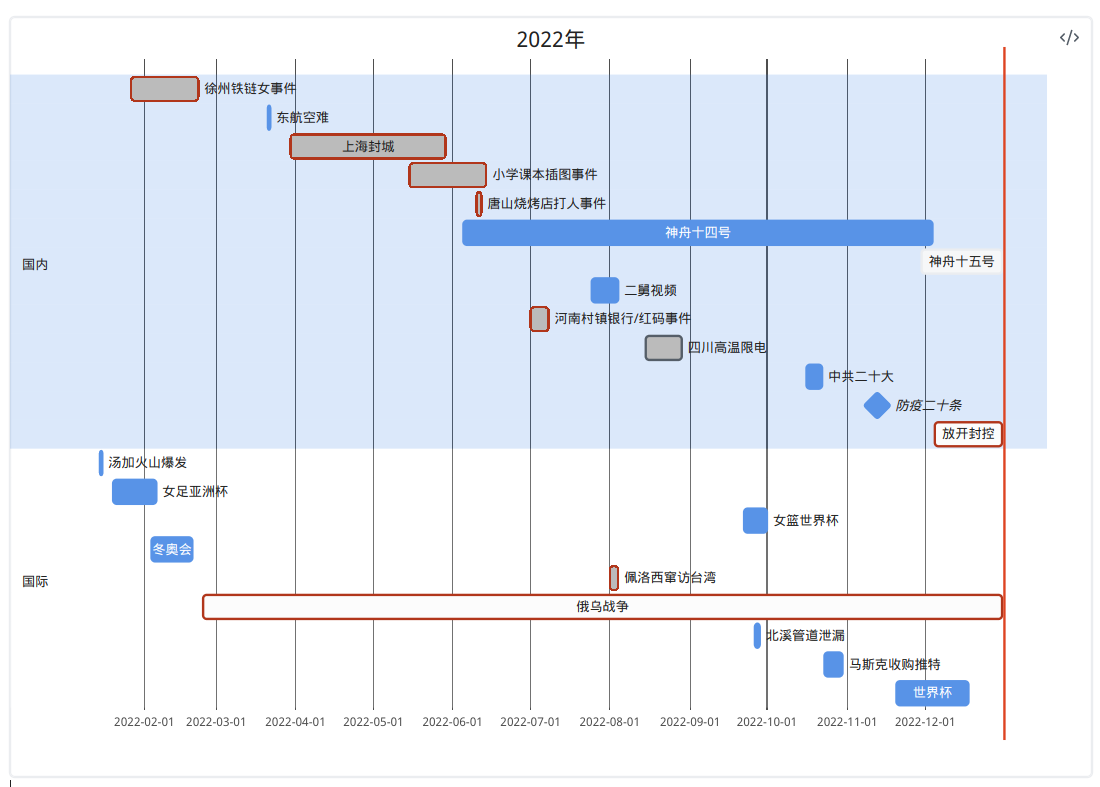
昨天突发奇想想总结一下2022年, 发现还是用mermaid的甘特图做最简单. 鼓捣一番以后在朋友圈里发了这张图:
今天简单总结一下mermaid的甘特图(gantt chart)语法, 因为昨天感觉mermaid官网的gantt文档 只给了几个例子 不太适合上手.
mermaid.js
mermaid.js是一个用来在网页中生成图表的库. 使用简单的语法来描述图表, 通过 JavaScript渲染.
支持生成多种类型的图表, 例如流程图/时序图/甘特图等等.
Mermaid.js 的目标是让生成图表变得简单而且易于使用, 让用户能够更专注于图表的内容和信息的传递而不是图表的排版.
它的理念和markdown/graphviz一样, 用代码代替富文本(word/powerpoint/画图工具), 这样做的好处有:
- 文件超小(只是文本文件), 打开和修改很方便
- 生成的图片是SVG, 不但美观还可以无损缩放
- 方便版本管理(git)
之前我试过mermaid的流程图(flow chart), 感觉不如graphviz灵活(虽然语法更简洁). 但是mermaid被许多markdown编辑器支持, 而且覆盖了很多类型的图表 ...